Polkadot/Substrate Manifest File
Polkadot/Substrate Manifest File
The Manifest project.ts file can be seen as an entry point of your project and it defines most of the details on how SubQuery will index and transform the chain data. It clearly indicates where we are indexing data from, and to what on chain events we are subscribing to.
The Manifest can be in either Typescript, Yaml, or JSON format.
With the number of new features we are adding to SubQuery, and the slight differences between each chain that mostly occur in the manifest, the project manifest is now written by default in Typescript. This means that you get a fully typed project manifest with documentation and examples provided your code editor.
Below is a standard example of a basic project.ts.
import {
SubstrateDatasourceKind,
SubstrateHandlerKind,
SubstrateProject,
} from "@subql/types";
// Can expand the Datasource processor types via the genreic param
const project: SubstrateProject = {
specVersion: "1.0.0",
version: "0.0.1",
name: "polkadot-starter",
description:
"This project can be used as a starting point for developing your SubQuery project",
runner: {
node: {
name: "@subql/node",
version: ">=3.0.1",
},
query: {
name: "@subql/query",
version: "*",
},
},
schema: {
file: "./schema.graphql",
},
network: {
/* The genesis hash of the network (hash of block 0) */
chainId:
"0x91b171bb158e2d3848fa23a9f1c25182fb8e20313b2c1eb49219da7a70ce90c3",
/**
* This endpoint must be a public non-pruned archive node
* Public nodes may be rate limited, which can affect indexing speed
* When developing your project we suggest getting a private API key
*/
endpoint: "https://polkadot.rpc.subquery.network/public",
},
dataSources: [
{
kind: SubstrateDatasourceKind.Runtime,
startBlock: 1,
mapping: {
file: "./dist/index.js",
handlers: [
/*{
kind: SubstrateHandlerKind.Block,
handler: "handleBlock",
filter: {
modulo: 100,
},
},*/
/*{
kind: SubstrateHandlerKind.Call,
handler: "handleCall",
filter: {
module: "balances",
},
},*/
{
kind: SubstrateHandlerKind.Event,
handler: "handleEvent",
filter: {
module: "balances",
method: "Deposit",
},
},
],
},
},
],
};
// Must set default to the project instance
export default project;Below is a standard example of the legacy YAML version (project.yaml).
Legacy YAML Manifest
specVersion: 1.0.0
name: subquery-starter
version: 0.0.1
runner:
node:
name: "@subql/node"
version: "*"
query:
name: "@subql/query"
version: "*"
description: "This project can be use as a starting point for developing your Polkadot based SubQuery project"
repository: https://github.com/subquery/subql-starter
schema:
file: ./schema.graphql
network:
chainId: "0x91b171bb158e2d3848fa23a9f1c25182fb8e20313b2c1eb49219da7a70ce90c3"
# This endpoint must be a public non-pruned archive node
# We recommend providing more than one endpoint for improved reliability, performance, and uptime
# Public nodes may be rate limited, which can affect indexing speed
# When developing your project we suggest getting a private API key
endpoint: ["https://polkadot.rpc.subquery.network/public"]
# Optionally provide the HTTP endpoint of a full chain dictionary to speed up processing
dictionary: "https://api.subquery.network/sq/subquery/polkadot-dictionary"
# Optionally provide a list of blocks that you wish to bypass
bypassBlocks: [1, 2, 100, "200-500"]
dataSources:
- kind: substrate/Runtime
startBlock: 1 # Block to start indexing from
mapping:
file: ./dist/index.js
handlers:
- handler: handleBlock
kind: substrate/BlockHandler
- handler: handleEvent
kind: substrate/EventHandler
filter:
module: balances
method: Deposit
- handler: handleCall
kind: substrate/CallHandlerOverview
Top Level Spec
| Field | v1.0.0 | v0.2.0 | Description |
|---|---|---|---|
| specVersion | String | String | The spec version of the manifest file |
| name | String | String | Name of your project |
| version | String | String | Version of your project |
| description | String | String | Discription of your project |
| repository | String | String | Git repository address of your project |
| schema | Schema Spec | Schema Spec | The location of your GraphQL schema file |
| network | Network Spec | Network Spec | Detail of the network to be indexed |
| dataSources | DataSource Spec | DataSource Spec | The datasource to your project |
| templates | Templates Spec | Templates Spec | Allows creating new datasources from this templates |
| runner | Runner Spec | Runner Spec | Runner specs info |
Schema Spec
| Field | Type | Description |
|---|---|---|
| file | String | The location of your GraphQL schema file |
Network Spec
If you start your project by using the subql init command, you'll generally receive a starter project with the correct network settings. If you are changing the target chain of an existing project, you'll need to edit the Network Spec section of this manifest.
The chainId or genesisHash is the network identifier of the blockchain. In Substrate it is always the genesis hash of the network (hash of the first block). You can retrieve this easily by going to PolkadotJS and looking for the hash on block 0 (see the image below).
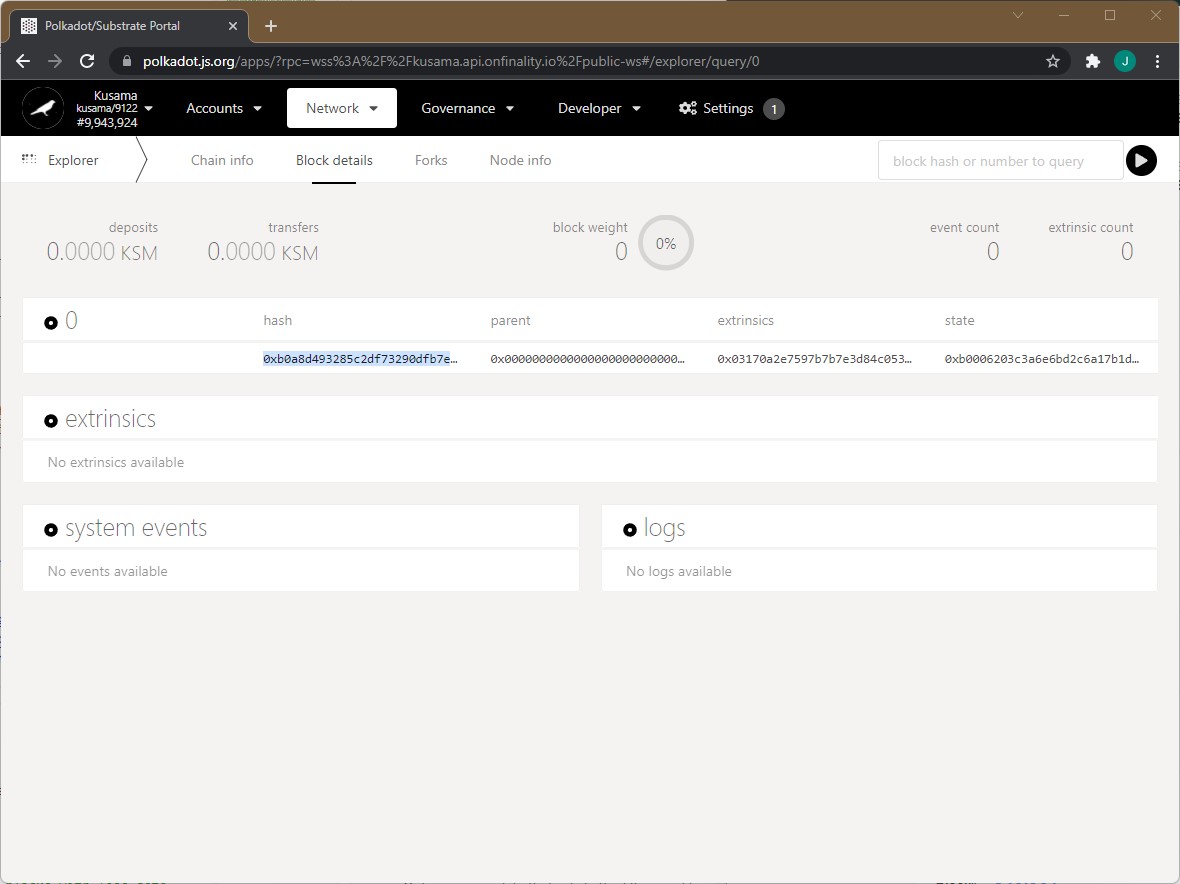
Additionally you will need to update the endpoint. This defines the (HTTP or WSS) endpoint of the blockchain to be indexed - this must be a full archive node. This property can be a string or an array of strings (e.g. endpoint: ['rpc1.endpoint.com', 'rpc2.endpoint.com']). We suggest providing an array of endpoints as it has the following benefits:
- Increased speed - When enabled with worker threads, RPC calls are distributed and parallelised among RPC providers. Historically, RPC latency is often the limiting factor with SubQuery.
- Increased reliability - If an endpoint goes offline, SubQuery will automatically switch to other RPC providers to continue indexing without interruption.
- Reduced load on RPC providers - Indexing is a computationally expensive process on RPC providers, by distributing requests among RPC providers you are lowering the chance that your project will be rate limited.
Public nodes may be rate limited which can affect indexing speed, when developing your project we suggest getting a private API key from a professional RPC provider.
| Field | v1.0.0 | Description |
|---|---|---|
| chainId | String | A network identifier for the blockchain (genesisHash in Substrate) |
| endpoint | String or String[] or Record<String, IEndpointConfig> | Defines the endpoint of the blockchain to be indexed, this can be a string, an array of endpoints, or a record of endpoints to endpoint configs - This must be a full archive node. |
| dictionary | String | It is suggested to provide the HTTP endpoint of a full chain dictionary to speed up processing - read how a SubQuery Dictionary works. |
| chaintypes | {file:String} | Path to chain types file, accept .json or .yaml format |
| bypassBlocks | Array | Bypasses stated block numbers, the values can be a range(e.g. "10- 50") or integer, see Bypass Blocks |
Runner Spec
| Field | v1.0.0 | Description |
|---|---|---|
| node | Runner node spec | Describe the node service use for indexing |
| query | Runner query spec | Describe the query service |
Runner Node Spec
| Field | v1.0.0 | Description |
|---|---|---|
| name | String | We currently support @subql/node |
| version | String | Version of the indexer Node service, it must follow the SEMVER rules or latest, you can also find available versions in subquery SDK releases |
| options | Runner Node Options | Runner specific options for how to run your project. These will have an impact on the data your project produces. CLI flags can be used to override these. |
Runner Query Spec
| Field | All manifest versions | Description |
|---|---|---|
| name | String | We currently support @subql/query |
| version | String | Version of the Query service, available @subql/query versions and @subql/query-subgraph versions, it also must follow the SEMVER rules or latest. |
Runner Node Options
| Field | v1.0.0 (default) | Description |
|---|---|---|
| historical | Boolean (true) | Historical indexing allows you to query the state at a specific block height. e.g A users balance in the past. |
| unfinalizedBlocks | Boolean (false) | If enabled unfinalized blocks will be indexed, when a fork is detected the project will be reindexed from the fork. Requires historical. |
| unsafe | Boolean (false) | Removes all sandbox restrictions and allows access to all inbuilt node packages as well as being able to make network requests. WARNING: this can make your project non-deterministic. |
| skipTransactions | Boolean (false) | If your project contains only event handlers and you don't access any other block data except for the block header you can speed your project up. Handlers should be updated to use LightSubstrateEvent instead of SubstrateEvent to ensure you are not accessing data that is unavailable. |
Datasource Spec
Defines the data that will be filtered and extracted and the location of the mapping function handler for the data transformation to be applied.
| Field | Type | Description |
|---|---|---|
| kind | String | substrate/Runtime |
| startBlock | Integer | This changes your indexing start block for this datasource, set this as high as possible to skip initial blocks with no relevant data |
| endBlock | Integer | This sets a end block for processing on the datasource. After this block is processed, this datasource will no longer index your data. Useful when your contracts change at a certain block height, or when you want to insert data at genesis. For example, setting both the startBlock and endBlock to 320, will mean this datasource only operates on block 320 |
| mapping | Mapping Spec |
Mapping Spec
| Field | All manifest versions | Description |
|---|---|---|
| handlers & filters | Default handlers and filters, Custom handlers and filters | List all the mapping functions and their corresponding handler types, with additional mapping filters. For custom runtimes mapping handlers please view Custom data sources |
Data Sources and Mapping
In this section, we will talk about the default Substrate runtime and its mapping. Here is an example:
{
...
dataSources: [
{
kind: SubstrateDataSourceKind.Runtime, // Indicates that this is default runtime
startBlock: 1, // This changes your indexing start block, set this higher to skip initial blocks with less data
mapping: {
file: "./dist/index.js", // Entry path for this mapping
handlers: [
/* Enter handers here */
],
}
}
]
}Mapping Handlers and Filters
The following table explains filters supported by different handlers.
Your SubQuery project will be much more efficient when you only use event and call handlers with appropriate mapping filters.
| Handler | Supported filter |
|---|---|
| substrate/BlockHandler | specVersion, modulo, timestamp |
| substrate/EventHandler | module,method |
| substrate/CallHandler | module,method ,success, isSigned |
Default runtime mapping filters are an extremely useful feature to decide what block, event, or extrinsic will trigger a mapping handler.
Only incoming data that satisfies the filter conditions will be processed by the mapping functions. Mapping filters are optional but are highly recommended as they significantly reduce the amount of data processed by your SubQuery project and will improve indexing performance.
# Example filter from Substrate callHandler
filter:
module: balances
method: Deposit
success: true
isSigned: trueThe specVersion filter specifies the spec version range for a Substrate block. The following examples describe how to set version ranges.
filter:
specVersion: [23, 24] # Index block with specVersion in between 23 and 24 (inclusive).
specVersion: [100] # Index block with specVersion greater than or equal 100.
specVersion: [null, 23] # Index block with specVersion less than or equal 23.The modulo filter allows handling every N blocks, which is useful if you want to group or calculate data at a set interval. The following example shows how to use this filter.
filter:
modulo: 50 # Index every 50 blocks: 0, 50, 100, 150....The timestamp filter is very useful when indexing block data with specific time intervals between them. It can be used in cases where you are aggregating data on a hourly/daily basis. It can be also used to set a delay between calls to blockHandler functions to reduce the computational costs of this handler.
The timestamp filter accepts a valid cron expression and runs on schedule against the timestamps of the blocks being indexed. Times are considered on UTC dates and times. The block handler will run on the first block that is after the next iteration of the cron expression.
filter:
# This cron expression will index blocks with at least 5 minutes interval
# between their timestamps starting at startBlock given under the datasource.
timestamp: "*/5 * * * *"Note
We use the cron-converter package to generate unix timestamps for iterations out of the given cron expression. So, make sure the format of the cron expression given in the timestamp filter is compatible with the package.
Some common examples
# Every minute
timestamp: "* * * * *"
# Every hour on the hour (UTC)
timestamp: "0 * * * *"
# Every day at 1am UTC
timestamp: "0 1 * * *"
# Every Sunday (weekly) at 0:00 UTC
timestamp: "0 0 * * 0"Simplifying your Project Manifest for a large number contract addresses
If your project has the same handlers for multiple versions of the same type of contract your project manifest can get quite repetitive. e.g you want to index the transfers for many similar ERC20 contracts, there are ways to better handle a large static list of contract addresses.
Note that there is also dynamic datasources for when your list of addresses is dynamic (e.g. you use a factory contract).
Custom Chains
You can index data from custom Substrate chains by also including chain types in the manifest.
We support the additional types used by Substrate runtime modules, typesAlias, typesBundle, typesChain, and typesSpec are also supported.
In the example below, the network.chaintypes are pointing to a file that has all the custom types included, This is a standard chainspec file that declares the specific types supported by this blockchain in either .json, .yaml or .js format.
network:
genesisHash: "0x91b171bb158e2d3848fa23a9f1c25182fb8e20313b2c1eb49219da7a70ce90c3"
endpoint: "ws://host.kittychain.io/public-ws"
chaintypes:
file: ./types.json # The relative filepath to where custom types are storedTo use typescript for your chain types file include it in the src folder (e.g. ./src/types.ts), run yarn build and then point to the generated js file located in the dist folder.
network:
chaintypes:
file: ./dist/types.js # Will be generated after yarn run buildThings to note about using the chain types file with extension .ts or .js:
- Your manifest version must be v0.2.0 or above.
- Only the default export will be included in the polkadot api when fetching blocks.
Here is an example of a .ts chain types file:
import { typesBundleDeprecated } from "moonbeam-types-bundle";
export default { typesBundle: typesBundleDeprecated };Working Example
You can see the suggested method for connecting and retrieving custom chain types in SubQuery's Official Dictionary repository. Here you will find a dictionary project for each network with all the chain types correct inserted. We retrieve these definitions from the official Polkadot.js repo, where each network lists their their chaintypes.
For example, Acala publish an offical chain type definition to NPM. This is imported in your project's package.json like so:
{
...
"devDependencies": {
...
"@acala-network/type-definitions": "latest"
},
...
}The under /src/chaintypes.ts we define a custom export for Acala's types bundle from this package.
import { typesBundleForPolkadot } from "@acala-network/type-definitions";
export default { typesBundle: typesBundleForPolkadot };This is then exported in the package.json like so:
{
...
"devDependencies": {
...
"@acala-network/type-definitions": "latest"
},
"exports": {
"chaintypes": "src/chaintypes.ts"
}
...
}Finally, in the project.ts manifest, we can import this official types bundle as per standard:
{
network: {
chainId:
"0x91b171bb158e2d3848fa23a9f1c25182fb8e20313b2c1eb49219da7a70ce90c3",
endpoint: [
"wss://acala-polkadot.api.onfinality.io/public-ws",
"wss://acala-rpc-0.aca-api.network",
],
dictionary: "https://api.subquery.network/sq/subquery/acala-dictionary",
chaintypes: {
file: "./dist/chaintypes.js",
},
},
}Real-time indexing (Unfinalised Blocks)
As indexers are an additional layer in your data processing pipeline, they can introduce a massive delay between when an on-chain event occurs and when the data is processed and able to be queried from the indexer.
SubQuery provides real time indexing of unfinalised data directly from the RPC endpoint that solves this problem. SubQuery takes the most probabilistic data before it is finalised to provide to the app. In the unlikely event that the data isn’t finalised, SubQuery will automatically roll back and correct its mistakes quickly and efficiently - resulting in an insanely quick user experience for your customers.
To enable this feature, you must ensure that your project has the --unfinalized-blocks command enabled as well as historic indexing (enabled by default)
Bypass Blocks
Bypass Blocks allows you to skip the stated blocks, this is useful when there are erroneous blocks in the chain or when a chain skips a block after an outage or a hard fork. It accepts both a range or single integer entry in the array.
When declaring a range use an string in the format of "start - end". Both start and end are inclusive, e.g. a range of "100-102" will skip blocks 100, 101, and 102.
{
network: {
bypassBlocks: [1, 2, 3, "105-200", 290];
}
}Endpoint Config
This option allows specifying options that are applied specific to an endpoint. As of now this just allows setting headers on a per endpoint basis.
Here is an example of how to set an API key in the header of RPC requests in your endpoint config.
{
network: {
endpoint: {
"https://polkadot.rpc.subquery.network/public": {
headers: {
"x-api-key": "your-api-key",
}
}
}
}
}Custom Data Sources
Custom Data Sources provide network specific functionality that makes dealing with data easier. They act as a middleware that can provide extra filtering and data transformation.
A good example of this is EVM support, having a custom data source processor for EVM means that you can filter at the EVM level (e.g. filter contract methods or logs) and data is transformed into structures farmiliar to the Ethereum ecosystem as well as parsing parameters with ABIs.
Custom Data Sources can be used with normal data sources.
Here is a list of supported custom datasources:
| Kind | Supported Handlers | Filters | Description |
|---|---|---|---|
| substrate/FrontierEvm | substrate/FrontierEvmEvent, substrate/FrontierEvmCall | See filters under each handlers | Provides easy interaction with EVM transactions and events on the Frontier EVM (widely used across Polkadot including in Moonbeam and Astar networks) |